S3 Vector Bucket 實戰:用 Amazon Nova 將最新內衣商品型錄變成可搜尋的向量知識庫
S3 Vector Bucket 實戰:用 Amazon Nova 將最新內衣商品型錄變成可搜尋的向量知識庫
S3 為 Simple Storage Service 是 AWS 最早推出的服務之一,
除了做為檔案儲存空間以外,
發展到後來除了設定 Lifecycle 來將資料降規刪除,
亦可託管靜態網站,
近年來 AI 浪潮來襲,
S3 在 2025 年也推出 S3 Vector Bucket,
做為向量儲存空間使用,
此篇文章將簡單說明,
如何使用 S3 Vector Bucket 做為 RAG,
實際時做出一個低成本知識檢索庫。
甚麼是 RAG
什麼是檢索增強生成?
擷取增強生成 (RAG) 是對大型語言模型輸出最佳化的過程,
因此在產生回應之前,
它會參考其訓練資料來源以外的權威知識庫。
大型語言模型 (LLM) 在大量資料上訓練,
並使用數十億個參數來生成原始輸出,
用於回答問題、翻譯語言和完成句子等任務。
RAG 將原本就很強大的 LLM 功能擴展到特定領域或組織的內部知識庫,
而無需重新訓練模型。
這是改善 LLM 輸出具成本效益的方法,
可讓 LLM 在各種情況下仍然相關、準確且有用。
擷取增強生成為何重要?
即使 LLM 已經相當成熟,
但是 AI 幻覺仍是偶而會遇到的問題,
為避免這問題除了微調模型以外,
直接為現成資料建立索引,
讓查詢結果直接框定範圍,
會是個另一個有效的解決方法。
甚麼是向量資料?
甚麼是向量資料
過往我們在資料庫裡面儲存的資料是純量資料,
向是年紀或是電話,
他是一個實際的值,
不過有一些資料通常我們不會直接存進資料庫中,
像是圖片、文件、聲音這些實體檔案,
這些檔案在經過大語言模型的分析後,
會把它轉成一串數字 [0.12, 0.98, -0.45…],
這些轉換後的數字通常表示的是一種關係是一種特徵值,
以圖片來說可能表示顏色、材質,
這就是一種向量資料。
資料庫有哪些?
關聯式資料庫
過往在開發 Web 應用或是系統時,
都會使用 MySQL、Postgres、Oracle、SQL Server,
這些資料庫中每個資料表需要定義欄位,
每張資料表的欄位不是動態擴增,
而在不同資料表之間會增加限制,
或是表達他們之間關係的設定,
具有這些性質的通常就是關聯式資料庫。
非關聯式資料庫
記憶體資料庫
Redis、Memcache 就是大家在開發網頁中,
最常拿來做為快取使用的記憶體資料庫。
圖形資料庫
通常稱 Graph Database,
Neo4J 算是這類資料庫中最常被大家提起的資料庫,
圖形資料庫意思不是儲存圖片,
而是資料結構中的 Graph 結構,
和關聯式資料庫不同的是,
不會去讓兩張表取聯集、差集,
使用指標表達資料之間的關聯。
搜尋型資料庫
Solr、ELK、Open Search Service 就是過往被拿來做為搜尋型資料庫(我個人習慣稱搜尋引擎資料庫)的兩個產品,
除了日誌分析以外,
也常被作為全文檢索,
雖然關聯式資料庫也可以做為類似用途,
不過關聯式資料庫如果將所有欄位建立索引,
有可能會大幅度增加資料庫空間,
也降低資料庫的查詢效能,
與關聯式不同的搜尋型資料庫,
這類搜尋型資料庫原生就是全欄位索引,
具有評分機制和模糊查詢,
不是根據條件不符合就過濾掉,
而是會找出最接近你要的資料,
各方面而言都是進化版的 S3 Vector Bucket,
因此如果規模成長,
將不會使用 S3 Vector 做為向量資料的查詢,
S3 Vector Bucket 只會是資料中繼站,
最終資料會進到這類資料庫以便後續被高效查詢。
實作:建立 S3 Vector Bucket 並寫入向量資料
背景知識說完了,接著直接動手做。
本節將使用 AWS CloudShell 操作,不需要在本地安裝任何工具,只要登入 AWS Console 即可跟著操作。
實作過程中需要有 Bedrock 和 S3 相關的權限,請確認自己是不是有相關的權限。
Step 0:確認自己是否具有權限
無論是使用 IAM User 的 Credentials 還是 Single Sign On Mapping 至一個 IAM Role,
都需要確認自己是不是有調用 AWS Bedrock 模型的權限,
以及建立操作 S3 Bucket 和 S3 Vector Bucket 的權限
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ImageBucket",
"Effect": "Allow",
"Action": [
"s3:CreateBucket",
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::markmew-bra-image",
"arn:aws:s3:::markmew-bra-image/*"
]
},
{
"Sid": "S3VectorBucket",
"Effect": "Allow",
"Action": [
"s3vectors:CreateVectorBucket",
"s3vectors:GetIndex",
"s3vectors:CreateIndex",
"s3vectors:PutVectors",
"s3vectors:QueryVectors"
],
"Resource": "*"
},
{
"Sid": "BedrockInvokeModel",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/amazon.nova-2-multimodal-embeddings-v1:0"
}
]
}
以下範例會使用的模型是 amazon.nova-2-multimodal-embeddings, 這模型在 ap-northeast-1 還沒有開放, 設定權限時需確認使用的模型, 在該區是否已經開放使用。
Step 1:建立 S3 Vector Bucket
進入 AWS Console,在右上角開啟 CloudShell。
S3 Vector Bucket 目前需要透過 AWS CLI 建立,尚未整合進 S3 Console 的 UI,請執行以下指令:
1
2
3
aws s3vectors create-vector-bucket \
--vector-bucket-name markmew-s3-vector \
--region ap-northeast-1
Step 2:建立 S3 Bucket
建立用來存放圖片的 S3 Bucket,
這個 Bucket 是用來素材使用,
這些素材最後會被大語言模型轉化成向量資料後,
存進第一步的 S3 Vector Bucket 中
1
2
3
4
aws s3api create-bucket \
--bucket markmew-bra-image \
--region ap-northeast-1 \
--create-bucket-configuration LocationConstraint=ap-northeast-1
Step 3:上傳素材圖片
Bucket 建立完成後,進入 S3 Console 找到 markmew-bra-image,點擊右上角 Upload。
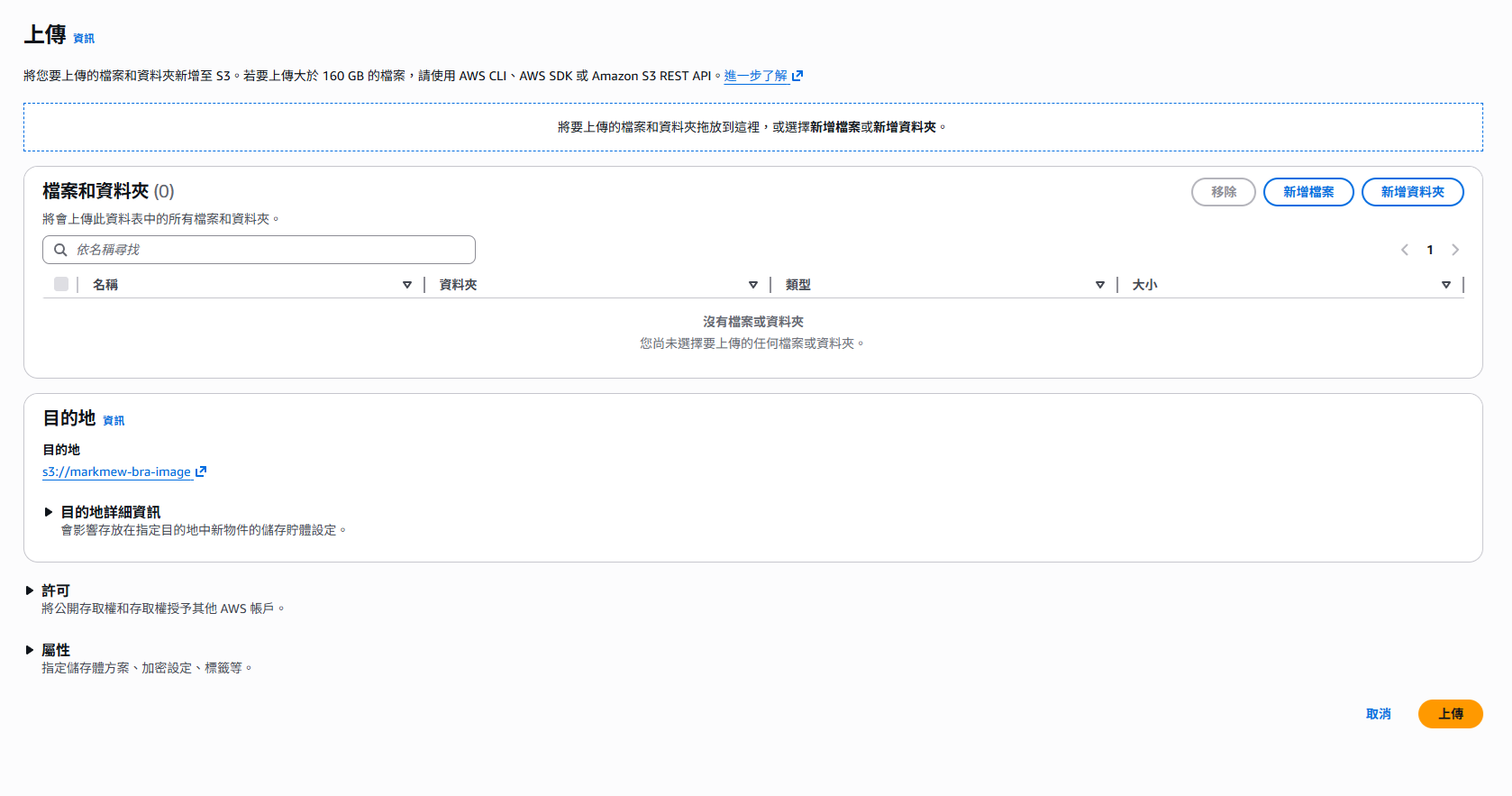
點擊 Add files 或直接將圖片拖曳進來選取要上傳的圖片。
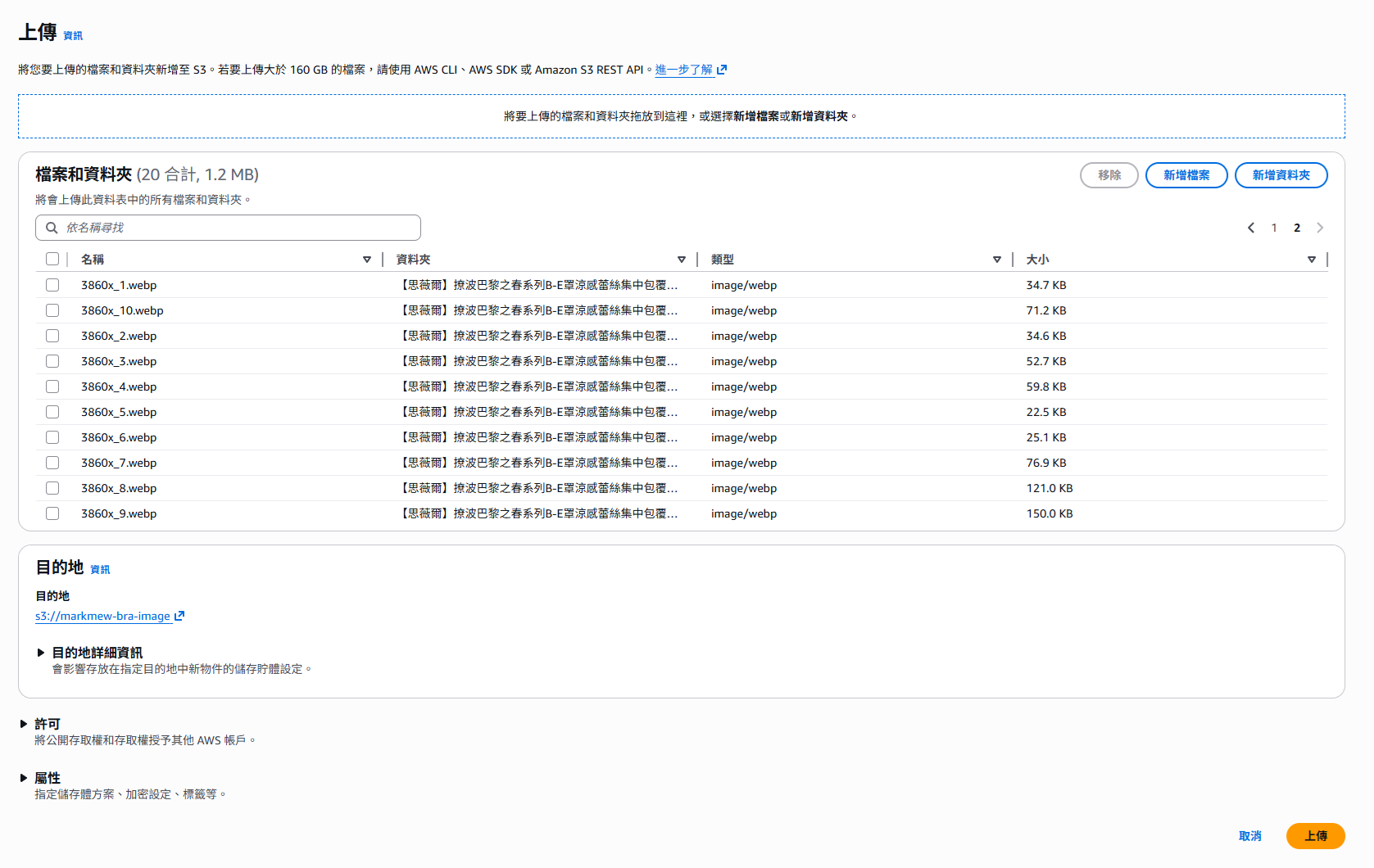
確認檔案清單後點擊 Upload,等待上傳完成即可看到圖片出現在 Bucket 中。
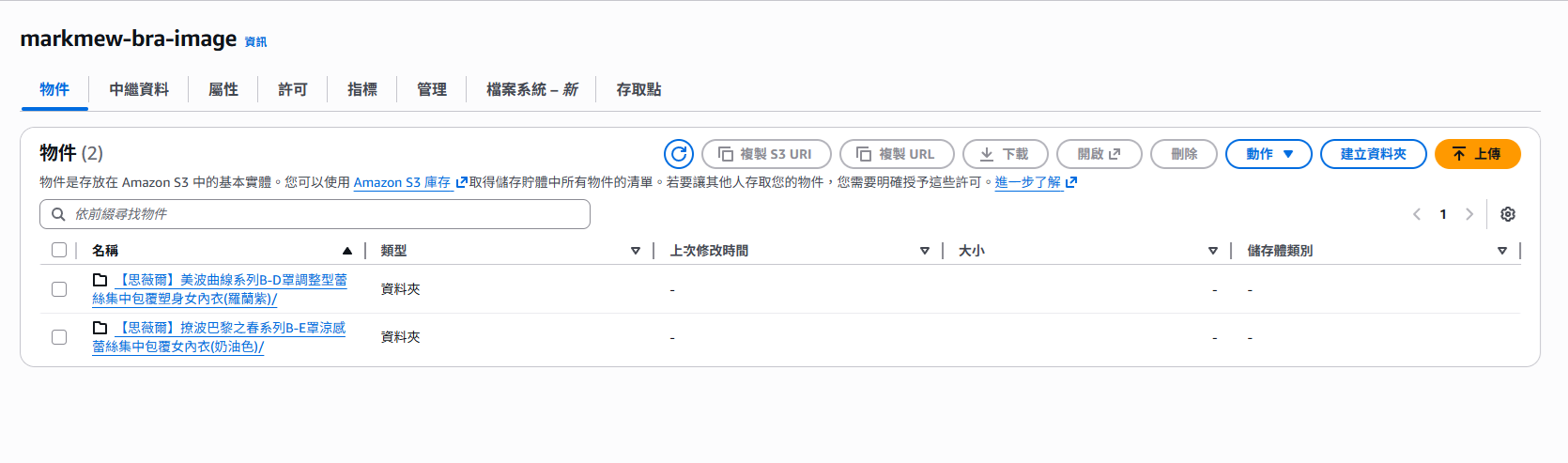
Step 3:建立 Index 並執行向量寫入與查詢
確認 Vector Bucket 建立完成後,執行以下 Python 腳本,腳本會依序建立 Index、將 S3 中的圖片轉成向量寫入,最後進行文字查詢測試。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
import boto3
import base64
import json
# --- 設定 ---
S3_REGION = 'ap-northeast-1'
BEDROCK_REGION = 'us-east-1' # Nova 只在 us-east-1 可用
S3_VECTORS_REGION = 'ap-northeast-1'
IMAGE_BUCKET_NAME = 'markmew-bra-image'
VECTOR_BUCKET_NAME = 'markmew-s3-vector'
NOVA_INDEX_NAME = 'bra-nova-multimodal-1024-cosine'
EMBEDDING_DIMENSION = 1024
# 建立客戶端
s3_client = boto3.client('s3', region_name=S3_REGION)
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=BEDROCK_REGION)
s3_vectors_client = boto3.client('s3vectors', region_name=S3_VECTORS_REGION)
def create_nova_multimodal_index():
"""建立 Nova 多模態向量索引"""
try:
s3_vectors_client.get_index(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=NOVA_INDEX_NAME
)
print(f"✅ Nova 多模態索引 {NOVA_INDEX_NAME} 已存在")
except Exception:
print(f"🚀 正在建立 Nova 多模態索引...")
s3_vectors_client.create_index(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=NOVA_INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType='float32',
distanceMetric='cosine'
)
print(f"✅ Nova 多模態索引建立完成")
def process_images_with_nova_fixed():
"""使用修正的 Nova API 格式處理圖片"""
print("🚀 使用 Amazon Nova Multimodal Embeddings (修正版) 處理圖片...")
paginator = s3_client.get_paginator('list_objects_v2')
pages = paginator.paginate(Bucket=IMAGE_BUCKET_NAME)
count = 0
vectors_batch = []
for page in pages:
if 'Contents' not in page:
continue
for obj in page['Contents']:
key = obj['Key']
if not key.lower().endswith(('.png', '.jpg', '.jpeg', '.webp')):
continue
print(f"正在處理: {key}")
try:
# 1. 讀取圖片
image_obj = s3_client.get_object(Bucket=IMAGE_BUCKET_NAME, Key=key)
image_bytes = image_obj['Body'].read()
if len(image_bytes) > 25 * 1024 * 1024:
print(f" ↳ ⚠️ 跳過: 圖片大小超過 25MB")
continue
# 2. 使用正確的 Nova API 格式
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX", # 必需參數
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "webp" if key.lower().endswith('.webp') else "jpeg",
"source": {
"bytes": base64.b64encode(image_bytes).decode('utf-8')
}
}
}
}
response = bedrock_runtime_client.invoke_model(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
body=json.dumps(request_body),
contentType="application/json"
)
response_data = json.loads(response['body'].read())
vector = response_data['embeddings'][0]['embedding']
# 3. 準備向量資料
vector_data = {
"key": f"nova-{count}",
"data": {"float32": vector},
"metadata": {
's3_uri': f's3://{IMAGE_BUCKET_NAME}/{key}',
'original_filename': key,
'type': 'nova_multimodal'
}
}
vectors_batch.append(vector_data)
print(f" ↳ ✅ Nova 向量生成成功 (ID: nova-{count})")
count += 1
# 批次插入
if len(vectors_batch) >= 50:
s3_vectors_client.put_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=NOVA_INDEX_NAME,
vectors=vectors_batch
)
print(f" ↳ 📦 已批次插入 {len(vectors_batch)} 個向量")
vectors_batch = []
except Exception as e:
print(f" ↳ ❌ 錯誤: {e}")
# 處理剩餘向量
if vectors_batch:
s3_vectors_client.put_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=NOVA_INDEX_NAME,
vectors=vectors_batch
)
print(f"📦 已插入最後 {len(vectors_batch)} 個向量")
print(f"\n🎉 Nova 處理完成!共處理 {count} 張圖片")
def query_by_text_with_nova_fixed(search_text, top_k=5):
"""使用修正的 Nova API 格式進行文字查詢"""
try:
print(f"🔍 使用 Nova 進行文字查詢: {search_text}")
# 使用正確的 API 格式
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL", # 查詢時使用 RETRIEVAL
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {
"truncationMode": "END",
"value": search_text
}
}
}
response = bedrock_runtime_client.invoke_model(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
body=json.dumps(request_body),
contentType="application/json"
)
response_data = json.loads(response['body'].read())
query_vector = response_data['embeddings'][0]['embedding']
# 搜索
search_response = s3_vectors_client.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=NOVA_INDEX_NAME,
queryVector={"float32": query_vector},
topK=top_k,
returnDistance=True,
returnMetadata=True
)
print(f"📊 Nova 文字查詢結果:")
print("-" * 80)
for i, result in enumerate(search_response['vectors']):
distance = result.get('distance', 0)
similarity = (1 - distance) * 100
s3_uri = result['metadata'].get('s3_uri', 'N/A')
filename = result['metadata'].get('original_filename', 'N/A')
print(f"{i+1:2d}. 相似度: {similarity:6.2f}%")
print(f" 檔案: {filename}")
print(f" 位置: {s3_uri}")
print()
return search_response
except Exception as e:
print(f"❌ Nova 文字查詢失敗: {e}")
return None
def query_by_image_with_nova_fixed(image_key, top_k=5):
"""使用修正的 Nova API 格式進行圖片查詢"""
try:
print(f"🔍 使用 Nova 進行圖片查詢: {image_key}")
# 讀取圖片
image_obj = s3_client.get_object(Bucket=IMAGE_BUCKET_NAME, Key=image_key)
image_bytes = image_obj['Body'].read()
# 使用正確的 API 格式
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL", # 查詢時使用 RETRIEVAL
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "webp" if image_key.lower().endswith('.webp') else "jpeg",
"source": {
"bytes": base64.b64encode(image_bytes).decode('utf-8')
}
}
}
}
response = bedrock_runtime_client.invoke_model(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
body=json.dumps(request_body),
contentType="application/json"
)
response_data = json.loads(response['body'].read())
query_vector = response_data['embeddings'][0]['embedding']
# 搜索相似圖片
search_response = s3_vectors_client.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=NOVA_INDEX_NAME,
queryVector={"float32": query_vector},
topK=top_k,
returnDistance=True,
returnMetadata=True
)
print(f"📊 Nova 圖片查詢結果:")
print("-" * 80)
for i, result in enumerate(search_response['vectors']):
distance = result.get('distance', 0)
similarity = (1 - distance) * 100
s3_uri = result['metadata'].get('s3_uri', 'N/A')
filename = result['metadata'].get('original_filename', 'N/A')
print(f"{i+1:2d}. 相似度: {similarity:6.2f}%")
print(f" 檔案: {filename}")
print(f" 位置: {s3_uri}")
print()
return search_response
except Exception as e:
print(f"❌ Nova 圖片查詢失敗: {e}")
return None
if __name__ == "__main__":
print("🚀 使用修正的 Nova Multimodal Embeddings API")
print("=" * 70)
# 1. 建立索引
create_nova_multimodal_index()
print("\n" + "=" * 70)
# 2. 處理圖片
process_images_with_nova_fixed()
print("\n" + "=" * 70)
# 3. 測試文字查詢
print("🔍 測試 Nova 文字查詢:")
test_queries = [
"紫色內衣",
"蕾絲胸罩",
"奶油色內衣",
"調整型內衣"
]
for query in test_queries:
print(f"\n--- 查詢: {query} ---")
query_by_text_with_nova_fixed(query, top_k=3)
print("\n" + "=" * 70)
# 4. 測試圖片查詢(可選)
# print("🔍 測試 Nova 圖片查詢:")
# query_by_image_with_nova_fixed("your-image-file.webp", top_k=3)
在執行程式碼以後,
我們可以明確看到每張圖片執行結果,
以 紫色內衣 這個關鍵字為例,
確實可以明確看出來搜尋結果是抓取紫色資料夾中的產品,
而不是奶油色資料夾中的產品,
雖然素材不多,
不過結果來看姑且算是正確的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
~ $ python query_similar_images.py
/usr/local/lib/python3.9/site-packages/boto3/compat.py:89: PythonDeprecationWarning: Boto3 will no longer support Python 3.9 starting April 29, 2026. To continue receiving service updates, bug fixes, and security updates please upgrade to Python 3.10 or later. More information can be found here: https://aws.amazon.com/blogs/developer/python-support-policy-updates-for-aws-sdks-and-tools/
warnings.warn(warning, PythonDeprecationWarning)
🚀 使用修正的 Nova Multimodal Embeddings API
======================================================================
✅ Nova 多模態索引 bra-nova-multimodal-1024-cosine 已存在
======================================================================
🚀 使用 Amazon Nova Multimodal Embeddings (修正版) 處理圖片...
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_1.webp
↳ ✅ Nova 向量生成成功 (ID: nova-0)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_10.webp
↳ ✅ Nova 向量生成成功 (ID: nova-1)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_2.webp
↳ ✅ Nova 向量生成成功 (ID: nova-2)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_3.webp
↳ ✅ Nova 向量生成成功 (ID: nova-3)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_4.webp
↳ ✅ Nova 向量生成成功 (ID: nova-4)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_5.webp
↳ ✅ Nova 向量生成成功 (ID: nova-5)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_6.webp
↳ ✅ Nova 向量生成成功 (ID: nova-6)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_7.webp
↳ ✅ Nova 向量生成成功 (ID: nova-7)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_8.webp
↳ ✅ Nova 向量生成成功 (ID: nova-8)
正在處理: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_9.webp
↳ ✅ Nova 向量生成成功 (ID: nova-9)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_1.webp
↳ ✅ Nova 向量生成成功 (ID: nova-10)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_10.webp
↳ ✅ Nova 向量生成成功 (ID: nova-11)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_2.webp
↳ ✅ Nova 向量生成成功 (ID: nova-12)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_3.webp
↳ ✅ Nova 向量生成成功 (ID: nova-13)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_4.webp
↳ ✅ Nova 向量生成成功 (ID: nova-14)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_5.webp
↳ ✅ Nova 向量生成成功 (ID: nova-15)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_6.webp
↳ ✅ Nova 向量生成成功 (ID: nova-16)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_7.webp
↳ ✅ Nova 向量生成成功 (ID: nova-17)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_8.webp
↳ ✅ Nova 向量生成成功 (ID: nova-18)
正在處理: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
↳ ✅ Nova 向量生成成功 (ID: nova-19)
📦 已插入最後 20 個向量
🎉 Nova 處理完成!共處理 20 張圖片
======================================================================
🔍 測試 Nova 文字查詢:
--- 查詢: 紫色內衣 ---
🔍 使用 Nova 進行文字查詢: 紫色內衣
📊 Nova 文字查詢結果:
--------------------------------------------------------------------------------
1. 相似度: 40.29%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_8.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_8.webp
2. 相似度: 38.02%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
3. 相似度: 34.87%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_4.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_4.webp
--- 查詢: 蕾絲胸罩 ---
🔍 使用 Nova 進行文字查詢: 蕾絲胸罩
📊 Nova 文字查詢結果:
--------------------------------------------------------------------------------
1. 相似度: 41.13%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
2. 相似度: 39.92%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_1.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_1.webp
3. 相似度: 39.53%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_4.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_4.webp
--- 查詢: 奶油色內衣 ---
🔍 使用 Nova 進行文字查詢: 奶油色內衣
📊 Nova 文字查詢結果:
--------------------------------------------------------------------------------
1. 相似度: 46.78%
檔案: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_7.webp
位置: s3://markmew-bra-image/【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_7.webp
2. 相似度: 46.66%
檔案: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_4.webp
位置: s3://markmew-bra-image/【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_4.webp
3. 相似度: 45.41%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
--- 查詢: 調整型內衣 ---
🔍 使用 Nova 進行文字查詢: 調整型內衣
📊 Nova 文字查詢結果:
--------------------------------------------------------------------------------
1. 相似度: 54.27%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_10.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_10.webp
2. 相似度: 53.83%
檔案: 【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
位置: s3://markmew-bra-image/【思薇爾】美波曲線系列B-D罩調整型蕾絲集中包覆塑身女內衣(羅蘭紫)/3860x_9.webp
3. 相似度: 52.88%
檔案: 【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_9.webp
位置: s3://markmew-bra-image/【思薇爾】撩波巴黎之春系列B-E罩涼感蕾絲集中包覆女內衣(奶油色)/3860x_9.webp
======================================================================
結語
S3 Vector Bucket 是 AWS 在 AI 浪潮下推出的輕量向量儲存方案,
對於規模不大、想快速驗證想法的場景來說,
不需要額外維護 Pinecone、Weaviate 或 OpenSearch 這類向量資料庫,
直接用既有的 S3 生態系就能完成從圖片上傳、向量寫入到相似度查詢的完整流程。
當然,如同文章前半段提到的,
S3 Vector Bucket 目前不具備全文索引、評分機制等進階查詢能力,
如果資料量成長或查詢需求變複雜,
遷移到專職的向量資料庫會是必然的選擇,
把 S3 Vector Bucket 定位為 PoC 或低流量場景的中繼站會是比較合理的使用方式。
參考文件: